|
|
|
|
|
|
| |
| |
|
|
|
|
| |
| |
|
|
On 4/23/2011 4:08, Orchid XP v8 wrote:
> Not to my knowledge, no. It records who created a patch and when, but not
> when it was applied to any particular repo.
That seems a problem to me, yes. :-)
>> So if, for example, I'm working, and everything's good, and I take some
>> patches from you, then work some more, then take some patches from Sam,
>> then work some more, then run my test and it fails, can I figure out
>> that it was Sam's patches, even if he created those patches before I
>> even cloned the repository in the first place?
>
> In that case you're presumably going to revert patches until the problem
> goes away. Maybe one patch broke something, maybe its an interaction of
> several patches. You turn patches on and off until you figure out what's up.
Sure. But I can't tell after the fact when I sucked Sam's patch in, so if
Sam wrote the patch 2 months ago and I only started seeing the problem a
week ago, it's not obvious that it might actually be Sam's patch.
--
Darren New, San Diego CA, USA (PST)
"Coding without comments is like
driving without turn signals."
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
On 4/23/2011 4:15, Orchid XP v8 wrote:
> Hint: Look up "darcs fetch". It fetches changes without applying them.
OK. It sounded to me like Darcs had one working copy and one repository, and
applying all the patches from the repository would give you a "pristine"
version, and the working version was differenced from the pristine version
to get the next patch.
So it sounds like you can't actually fetch changes without having them
actually be relevant to the working directory. If you make the WD match the
repository, then fetch changes without applying them, then ask for diffs,
isn't Darcs going to tell you the WD doesn't match the repository? If your
change added the line ABC, isn't darcs diff going to tell you you removed
ABC from the WD?
So what do you mean "apply"? What happens if your WD matches the
repository, then you do a fetch, then you say "record", what does Darcs do?
> It's the fact that you have to commit the merged version of the file as a
> new version. Every time you merge in a new change, you have to commit a new
> version. It just seems clunky and unecessary.
It's mildly clunky, but it tells you which changes are applied to which
snapshots. git does this because it records files, not changes, yes. It's
probably the part of git that people like least.
What happens if I have a number of tags in the repository (v1 and v2 and the
current v3 under development), and I want to apply a bugfix to the v1
version that doesn't apply to the later versions? How do I do that?
>> In Darcs, that's one step it seems - I can't get changes
>> from you *without* applying them to the work I'm doing.
>
> Not true. You can get changes without applying them. It's just that usually,
> you want to fetch changes to, you know, *use* them.
But if you have multiple branches, like V1, V2, and V3beta1, and someone
sends you a new feature for V3beta1, you don't want to apply that to V1 or
V2. If you get a bugfix for V1 and make V1.01 you might or might not want
to apply that to V3.
> Then why fetch the changes at all? Why not wait until you're actually ready
> to apply them?
Welcome to DVCS!
Plus, what do you mean "apply"? git stores multiple branches in one
repository. I could as easily ask you "why wouldn't you apply every change
you get to every copy of the Darcs repository for your program?" The answer
is "because maybe I don't want to change that repository."
I might want to push changes up to a shared repository so everyone in the
team can work on them, but I don't want it going into production or even to
people not on the team.
I might want the development branch to apply the changes but not the branch
that's half way thru QA testing.
>> So if you have something like Linux, where there's a new release every
>> few months, you need a complete repository for every release.
>
> Um... why?
Because you don't want all the changes applied to old versions of Linux?
Maybe Darcs tags would do the trick there?
>> And if I
>> fix a bug in an old release and you want to incorporate that bug fix
>> into newer releases, what do you do?
>
> Oh, I see. You mean if you actually have multiple versions of something
> being developed concurrently? Yeah, in that case you'd have to move the
> changeset from one branch to another and hope it works.
And *that* is exactly what a git merge is. You don't do a merge every time
you record a change. You only do a merge when you're actually, you know,
merging two sets of changes into one branch of the repository.
A git branch is like a darcs repository.
A git commit is like a darcs record.
A git merge is like a darcs fetch-and-apply.
>>> You then have to
>>> *create a new commit object* representing this new combined state.
>>
>> Yes.
>
> So if two people have the same repo, and they merge in change X and then
> later merge in change Y, and then the other guy merges in change Y first and
> later change X, they now apparently have conflicting histories.
Well, you don't really "merge in" a change. You merge a change from one
branch to another. You're not merging changes, you're merging branches.
You're not going to have conflicting histories. Indeed, you *can't* have
conflicting histories because history is immutable. You might have different
histories in each repository, but that's like having two Darcs repositories
cloned from the same source but with a different set of changes in each.
So if we start at the same version, and you make three changes, and I make
three changes, and assuming there's no conflicts, when I merge your changes
into mine, I'll get the same files as if you merged my changes into yours,
so we'll both wind up with the same files, except yours will say yours
committed it and mine will say mine committed it.
Normally the only reason you'd both merge in the other person's changes is
if you're both going to keep developing on your own. Otherwise, what you
ought to do is I merge in your changes, and then give you the result to
continue from.
Obviously it's not a problem if you don't later combine the repositories
into one history. If you do, then you'll have two branches, and your pointer
will point to yours, and mine will point to mine, and they'll each be
pointing to a separate commit with the same files in each one (assuming
they're identical contents and that you didn't resolve merge conflicts
differently than I did).
> (And all
> because Git wants to pretend that everything happens in linear order.)
No, git very specifically does *not* pretend things happen in a linear
order. There's all kinds of tools to examine the DAG of dependencies
between versions.
> How do you get out of that?
If it comes time to turn your work and my work into the same branch, you
just merge the two branches in both repositories and work from there on,
which won't cause any merge conflicts because they're all the same files.
It's a DAG.
It would be similar in Darcs as if I set a tag in my repo and you set one in
your repo, then we merged them, and now you ask "how do you make a tag that
incorporates all the changes?" Well, if I took your changeset and you took
my change set, we'd have two tags. Make a third tag that points to the
combined set.
> As I say, it just annoys me that you have to assign an arbitrary ordering to
> changes.
It's not really arbitrary. Darcs just ignores the fact that they aren't.
If I add function AAA to file BBB and record that change, then add a call to
function AAA into file CCC, then record that change, would that really be
independent unordered changes in Darcs? That seems awfully fragile.
>> Say you have 25 changes in your Darcs repository, and you want a version
>> that applies every change except #23. What do you put in the repository
>> to represent that?
>
> You ask Darcs to revert change #23.
And how do you do that? "darcs revert" doesn't do that. "darcs unrecord"
throws the change away entirely. Obliterate deletes the patch entirely as well.
So it sounds like the actual answer is "you have to clone the entire
repository, then you have to obliterate the patch, and then you have to
rebuild the working directory from the new repository, and *then* you're
done, yes?
>>> It also irritates me that Git insists that even unrelated changes must
>>> have a linear time ordering.
>>
>> No they don't. Indeed, if unrelated changes had to have a linear time
>> ordering, you wouldn't get merge conflicts at all, would you?
>
> This doesn't make any sense to me at all...
Patches within any one branch have a linear time ordering. But git handles
multiple branches in the same repository. So changes between branches aren't
linearly ordered.
If changes were all linearly ordered, you'd never have to resolve merges,
because you could never have two independent patches trying to be applied to
the same place in the file, because one would definitely come before the
other, right?
Even on the same branch, while the changes are recorded linearly, if there
aren't conflicts between them, it's trivial to rearrange the order however
you want. Just like in Darcs you can't rearrange a patch that deletes a line
to be applied earlier than the patch that creates the line, so there's a
partial ordering in Darcs also. Same in git - it's a DAG with a partial
ordering. It's not linear.
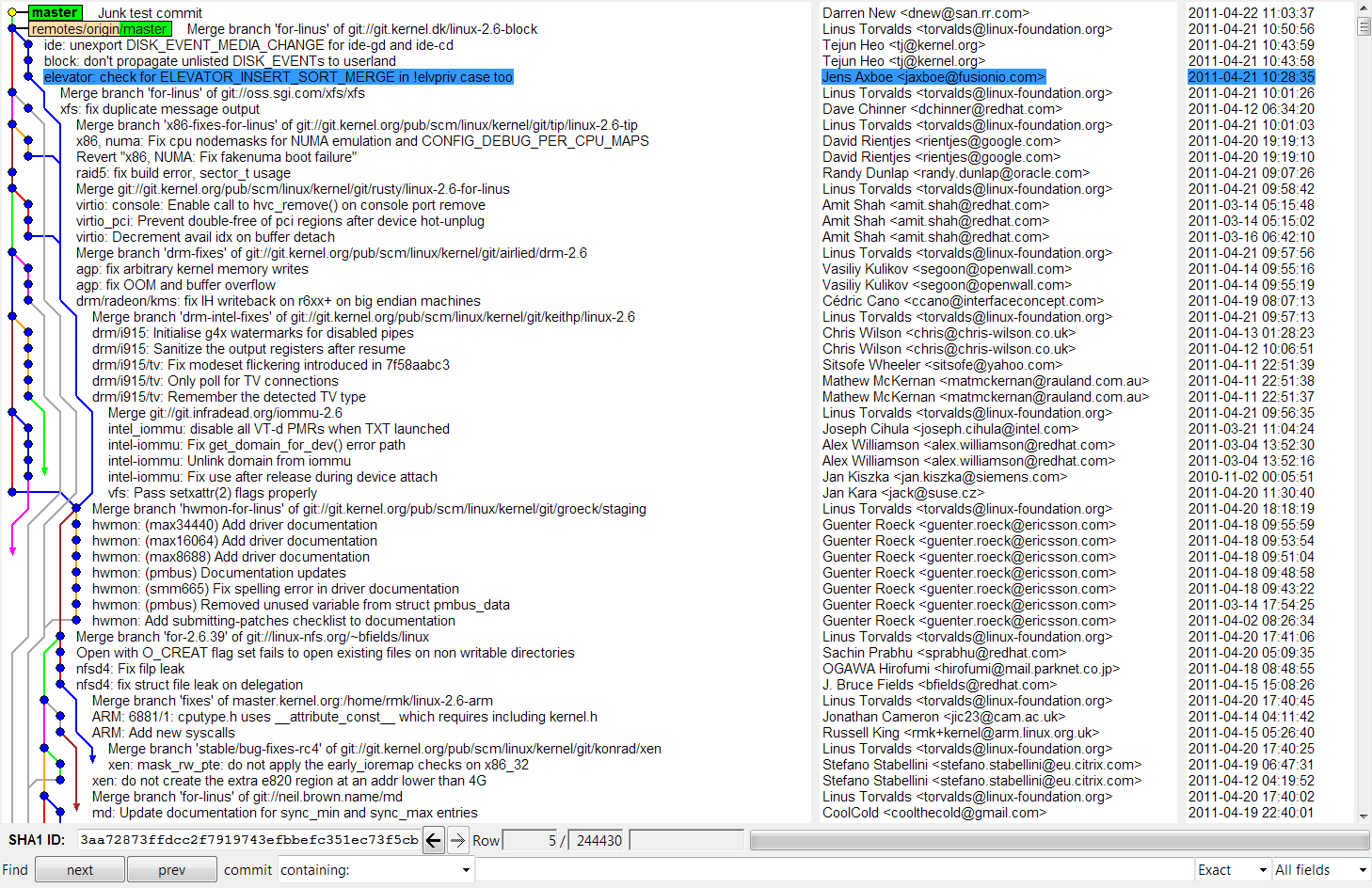
For example, attached is a picture of the last few dozen commits to the
Linux kernel.
--
Darren New, San Diego CA, USA (PST)
"Coding without comments is like
driving without turn signals."
Post a reply to this message
Attachments:
Download 'image1.png' (172 KB)
Preview of image 'image1.png'
|
|
| |
| |
|
|
|
|
| |
| |
|
|
On 4/23/2011 4:14, Orchid XP v8 wrote:
> Seems more like because it's so difficult to merge two files,
It's no more difficult in git than in darcs. It's exactly the same process.
You apply one set of diffs, then the other. If there are no conflicts,
you're done. If there are conflicts, you fix them, and you're done.
If there's a branch called "newstuff" and I'm working on "master", and I
want to merge in the changes from newstuff, I say
git merge newstuff
git commit
If file ABC has a conflict in it, I say
git merge newstuff
vi ABC
git add ABC
git commit
> after you've
> done it you have to save it to prevent you having to redo all that complex
> hard work.
Yes. Except it's exactly as hard and complex as in Darcs.
> And in the process, all change application is forced to become
> strictly linear.
git doesn't record changes, so no, change application isn't forced to become
linear.
> Apparently this doesn't stop people working on the Linux kernel. But it
> seems really clumsy to me.
It seems clumsy because you keep thinking git is recording changes. You keep
thinking of "changes" instead of "versions".
>> I'm not sure I'd want to check out something from Darcs that has a
>> quarter million patches in it and wait for Darcs to apply them all one
>> by one. How well does it handle that?
>
> You're aware that Darcs keeps a cached copy of the latest state of all the
> files, so it doesn't have to recompute them, right?
Sure.
> Last time I tried downloading the repos for GHC, it was dominated by network
> latency. Processor usage was almost non-existent. It just takes a long time
> to shift gigabytes of data over a slow ADSL link. Just as it would if I had
> downloaded a Zip file of the source code with no history data at all.
Yep. But you only got the latest version. If you wanted to get every tag,
you wind up copying all those files again anyway.
--
Darren New, San Diego CA, USA (PST)
"Coding without comments is like
driving without turn signals."
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
>> In that case you're presumably going to revert patches until the problem
>> goes away. Maybe one patch broke something, maybe its an interaction of
>> several patches. You turn patches on and off until you figure out
>> what's up.
>
> Sure. But I can't tell after the fact when I sucked Sam's patch in, so
> if Sam wrote the patch 2 months ago and I only started seeing the
> problem a week ago, it's not obvious that it might actually be Sam's patch.
Or, to summarise, "if I let my repo get 6 months out of date with the
upstream and then pull everything in at once and try to figure out why
it broke, it'll be quite difficult". My general reaction being "don't do
that", but OK, I guess it's a valid complaint...
--
http://blog.orphi.me.uk/
http://www.zazzle.com/MathematicalOrchid*
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
On 4/23/2011 4:21, Orchid XP v8 wrote:
>> "If the conflict is with one of your not-yet-published patches, you may
>> choose to amend that patch rather than creating a resolve patch."
>>
>> And that's exactly what the "git merge" command does.
>
> I thought "git merge" just combines changes, not resolves conflicts.
It doesn't. Altho there's the "git rerere" command, which resolves merge
conflicts the same way you did last time, if you want. :-)
What do you mean by "resolves conflicts"? That's a manual process in git and
in darcs.
> I wasn't even talking about conflicts. I'm talking about the fact that if
> the central repo changes, even in a way which does *not* conflict with your
> changes, you still have to update your local repo, remerge all the changes,
> and try again.
*If* you're *pushing* to a repository that is unattended, yes. How do you do
it in Darcs? What happens if people push conflicts into the central
repository? Is that where the "we ignore conflicts without telling you" part
comes in?
>> I'll grant you that Darcs is definitely simpler, but I think it's less
>> capable also, and that's the primary place the simplicity comes from.
>
> I disagree, but I don't think this argument is going anywhere productive
> right now.
It's less capable in that you only have one branch in a Darcs repository,
and you have no staging area where you can commit in sections. To the extent
that you avoid doing that in git, they seem pretty much identical to me.
> Yeah, it's only really useful for global names (e.g., functions or types).
Yeah, I try to avoid working in languages with global names. I honestly
don't really even know any languages like that any more. Even global names
in C aren't actually global.
> What should *really* happen is that Darcs looks at your edits and *detects*
> that it's a find-and-replace affecting only certain lines, and record that.
Yeah, when your repository system starts understanding that stuff, it has
some advantages. :-)
--
Darren New, San Diego CA, USA (PST)
"Coding without comments is like
driving without turn signals."
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
On 4/23/2011 10:38, Orchid XP v8 wrote:
>> But if they don't conflict, then that's one step. (Well, one step for
>> each of the 200 changes, just like in Darcs.)
>
> Except that you have to record the order you did it in, even though it
> doesn't actually matter.
You *can* do all 200 at once, if you want. It's just a mess to specify.
>> No, it doesn't really work like that. Like I said, of the Linux repo,
>> there's 240,000 commits, of which 15,000 are actually merges. Git has a
>> lot of ways of editing the history to make it look simpler, which is
>> where all the perceived complexity of git lies.
>
> I might suggest that if you *need* the ability to edit history to make it
> look simpler, you're doing it wrong.
One is editing history only to back out changes or rearrange commits. Once
it's in a repository anyone else can see, you can't edit it safely any more.
Just like Darcs.
> Except that with Darcs, you don't need to record the fact that a branch ever
> even existed. You just record what was done with the actual file contents.
I would classify that as a problem, not a benefit. I'd like to know which
patches were developed independently, when they were incorporated into the
current code, etc.
>> Well, here's the advantages of git, so far:
>>
>> Git can keep multiple branches in one repository
>
> I don't know how that works, but if you mean you can have multiple working
> copies, then yes, I guess that could be quite useful.
No. It's exactly like having multiple repositories in one directory.
Branching in git is cloning the repository in Darcs. Merging in git is a
pull in Darcs.
>> Git keeps track of where changes came from and when, so if I pull in a
>> 2-month-old changeset and it breaks something, I can figure out when I
>> pulled it in vs when you wrote the change.
>
> I'm not sure I see why you would need that information, but OK, Darcs can't
> tell you about that.
Because if you created a patch six months ago and I only applied it last
week, it would be good to know that when things start breaking, it *might*
be because of a change that I only saw a week ago, and I might have to go
back as far as six months worth of changes to understand the problem.
You really don't see the benefit of knowing the difference between "when I
wrote the code" and "when I gave you the code"? It's the same reason you
put version numbers on executable files you distribute - so you know what
you're running when.
>> git keeps a history that can tell me what changes rely on other changes
>> semantically, not just syntactically.
>
> How?
Exactly that "linear" order you're complaining about. The DAG of commits
tells you which changes were written with one version in mind but without
other changes in mind.
If I change on April 1 the semantics of function XYZ, then I write code on
April 3 depending on the new semantics, and you on April 5 write code
depending on the old semantics, you now have a dependency from your code to
the April 1 code that isn't recorded anywhere in Darcs. It's recorded in
git, tho.
If I have a repository and I merge in a bunch of your changes and apply
them, then I merge in a bunch of changes from Jim, I could very well get
tons of conflicts if Jim didn't apply your changes when he started working.
It seems fragile to me to have a working directory and a repository where I
can incorporate changes into the repository that I cannot get into the
working directory to work on.
>> git doesn't have to spend tens of hours applying 240,000 change sets to
>> the repository in order to give me the latest version of the files.
>
> Neither does Darcs.
Sure it does. Delete your working directory.
When you clone git, it pulls down the repository, then creates the working
directory from that. When you clone darcs, it sounds like it pulls down both
the repository and the working copy (which would seem problematic if the
working copy had changes to it that weren't recorded, yes?).
>> git has all kinds of sweet tools to manipulate the repository in ways
>> Darcs can't very easily.
>
> Ways such as what?
Like the bisecting command, just as an example. Or the stash command. Or
commiting things in phases. Or efficiently giving me a copy of the files as
they existed at a specific point in time. (Indeed, since Darcs doesn't
actually record what order you pulled changes in, it seems Darcs can't
really even do that inefficiently.)
>>> Still, until GHC moves from Darcs to Git, I won't have to actually
>>> care, so I guess it doesn't really matter.
>>
>> Not unless you wind up working on a project that uses git.
>
> That isn't going to happen.
BTW, if you ever want to play, there's a script for git that will import the
changes from and export to a Darcs repository.
http://vmiklos.hu/project/darcs-fast-export/git-darcs
Just from reading the comments, it looks like it stores the Darcs repository
as one branch of the git repository, treating it like a remote repository.
> 1. I will never wind up "working" on anything that's version-controlled. I
> am apparently doomed to spend the rest of my /working/ life rebooting
> people's PCs because Word crashed, rather than doing interesting coding tasks.
<Yoda> And that is why you fail. </Yoda>
> 2. If we're talking about hobby projects, obviously I'm going to pick one
> that uses my preferred tools.
Sure.
> It's not that I don't understand the difference between Git and Darcs. It's
> that I can't begin to comprehend how what Git does can work. It just seems
> such an obviously stupid way to approach the problem.
It seems like a tremendously elegant system to me, like the relational model
for version control. You have a big pile of snapshots, one for each
committed set of changes. All differences are calculated from the snapshots
as needed.
Darcs too is fairly elegant. If they had a more sophisticated way of
handling groupings of changes besides "clone the entire repository and then
make irreversable changes to it" it would be even better.
--
Darren New, San Diego CA, USA (PST)
"Coding without comments is like
driving without turn signals."
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
On 4/23/2011 10:48, Orchid XP v8 wrote:
> My general reaction being "don't do that",
Sounds like a problem for any dvcs. Some development cycles take a while,
you know? :-)
It seems like a problem exactly because darcs doesn't record what version of
the code you were using when you made a particular change. If I change
something "at the same time" as you change something that uses the old
version, there's nothing recording that you wrote that after I made my
change but before you actually knew about my change. *That* is the "linear"
bit you're complaining about in git.
--
Darren New, San Diego CA, USA (PST)
"Coding without comments is like
driving without turn signals."
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
On 23/04/2011 06:46 PM, Darren New wrote:
> If you make the WD match
> the repository, then fetch changes without applying them, then ask for
> diffs, isn't Darcs going to tell you the WD doesn't match the
> repository?
Yes.
> If your change added the line ABC, isn't darcs diff going to
> tell you you removed ABC from the WD?
I'm not precisely sure what you're asking.
> So what do you mean "apply"? What happens if your WD matches the
> repository, then you do a fetch, then you say "record", what does Darcs do?
Records a new patch reverting all the changes that you didn't apply,
presumably. (Of course, what it's *actually* going to do is prompt you
for which ones you want to record, but anyway...)
>> It's the fact that you have to commit the merged version of the file as a
>> new version. Every time you merge in a new change, you have to commit
>> a new version. It just seems clunky and unecessary.
>
> It's mildly clunky, but it tells you which changes are applied to which
> snapshots. git does this because it records files, not changes, yes.
> It's probably the part of git that people like least.
It's the part I least like, at any rate.
> What happens if I have a number of tags in the repository (v1 and v2 and
> the current v3 under development), and I want to apply a bugfix to the
> v1 version that doesn't apply to the later versions? How do I do that?
You can't really use tags for that; you'd have to have seperate repos
for v1, v2 and v3. Oh, you *can* put all the patches in one repo, but
it's going to get messy very quickly.
> I might want the development branch to apply the changes but not the
> branch that's half way thru QA testing.
The Darcs way to do this is to store copies that are meant to be
different in different places - which seems fairly logical to me.
(Admittedly a little inefficient on disk space...)
>> Oh, I see. You mean if you actually have multiple versions of something
>> being developed concurrently? Yeah, in that case you'd have to move the
>> changeset from one branch to another and hope it works.
>
> And *that* is exactly what a git merge is. You don't do a merge every
> time you record a change. You only do a merge when you're actually, you
> know, merging two sets of changes into one branch of the repository.
You don't do a merge every time you record a change. You do a merge
every time somebody *else* records a change.
> A git branch is like a darcs repository.
> A git commit is like a darcs record.
> A git merge is like a darcs fetch-and-apply.
Except that you don't explicitly keep a record of a darcs fetch-and-apply.
>> So if two people have the same repo, and they merge in change X and then
>> later merge in change Y, and then the other guy merges in change Y
>> first and
>> later change X, they now apparently have conflicting histories.
>
> Well, you don't really "merge in" a change. You merge a change from one
> branch to another. You're not merging changes, you're merging branches.
>
> You're not going to have conflicting histories. Indeed, you *can't* have
> conflicting histories because history is immutable. You might have
> different histories in each repository, but that's like having two Darcs
> repositories cloned from the same source but with a different set of
> changes in each.
So what you're saying is, the histories in two Git repos don't actually
have to match, only the file contents?
>> (And all
>> because Git wants to pretend that everything happens in linear order.)
>
> No, git very specifically does *not* pretend things happen in a linear
> order. There's all kinds of tools to examine the DAG of dependencies
> between versions.
OK, "linear order within a single branch".
>> As I say, it just annoys me that you have to assign an arbitrary
>> ordering to changes.
>
> It's not really arbitrary. Darcs just ignores the fact that they aren't.
>
> If I add function AAA to file BBB and record that change, then add a
> call to function AAA into file CCC, then record that change, would that
> really be independent unordered changes in Darcs? That seems awfully
> fragile.
Darcs doesn't guarantee that a particular combination of patches will
produce a working combination of files. Neither does Git, or RCS, or
CVS. Git /assumes/ that if you apply the changes in the same order that
the author did, this is more likely to produce a working configuration,
but there's no /guarantee/ at all.
Changes have descriptions for a reason.
>>> Say you have 25 changes in your Darcs repository, and you want a version
>>> that applies every change except #23. What do you put in the repository
>>> to represent that?
>>
>> You ask Darcs to revert change #23.
>
> And how do you do that? "darcs revert" doesn't do that. "darcs unrecord"
> throws the change away entirely. Obliterate deletes the patch entirely
> as well.
"darcs rollback" does it though.
> Patches within any one branch have a linear time ordering. But git
> handles multiple branches in the same repository. So changes between
> branches aren't linearly ordered.
OK, fair enough. But changes within a branch are linearly ordered.
> For example, attached is a picture of the last few dozen commits to the
> Linux kernel.
What we see here is a long tangled history of sequential changes, rather
than a set of mostly independent changes which could safely be combined
in any combination.
--
http://blog.orphi.me.uk/
http://www.zazzle.com/MathematicalOrchid*
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
On 4/23/2011 10:38, Orchid XP v8 wrote:
>> git has all kinds of sweet tools to manipulate the repository in ways
>> Darcs can't very easily.
>
> Ways such as what?
Here's another example of something I don't understand how to do in Darcs.
Say you and I are both working on the same program. I find a bug in function
ABC that needs a counter incremented in a loop. At the start of the loop, I
add the counter increment. You, at the "same time", find the same bug and
fix it by adding the counter increment to the end of the loop.
Now, when we merge repositories, we'll be incrementing the counter twice.
OK, not a problem that a VCS can solve, and you'd get the same ugly in git.
But ... OK, so I see you fixed the bug by adding the counter at the bottom,
and since I already fixed it, I throw away that change from my repository.
You see you already fixed it, so you throw away my change in *your* repository.
How do we reconcile that later? How often do I have to exclude your change
from my repository (while still obtaining your other changes), or how do I
tell you to throw away your change and use mine instead?
In git, I'd manipulate the branch structure, or possibly rebase my changes,
or I'd revert out that one change from my code during the merge and continue
on. But since Darcs apparently doesn't record "they both started from the
same place and made changes in parallel",
I don't see how Darcs can rationally handle the *history* of this change,
other than having one or the other of us record a change that deletes the
line that we added, then distributing that change around. I.e., I don't see
how you can say "add this line, but delete that line it only if you apply
the patch that fixes the problem elsewhere" in any sort of managable way.
--
Darren New, San Diego CA, USA (PST)
"Coding without comments is like
driving without turn signals."
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
>> Apparently this doesn't stop people working on the Linux kernel. But it
>> seems really clumsy to me.
>
> It seems clumsy because you keep thinking git is recording changes. You
> keep thinking of "changes" instead of "versions".
That's because "changes" are the logical thing to think about. Take a
look at a bunch of commit messages, and they all tell you about what
just *changed*.
>> Last time I tried downloading the repos for GHC, it was dominated by
>> network latency. Processor usage was almost non-existent.
>
> Yep. But you only got the latest version. If you wanted to get every
> tag, you wind up copying all those files again anyway.
Um... why? The tags are downloaded along with all the rest of the history.
Or perhaps you meant if I wanted GHC-6.6 and GHC-HEAD? In which case, I
gather that Darcs caches patches which have recently been downloaded, so
I would only have to download the handful of patches which are actually
different between the two.
--
http://blog.orphi.me.uk/
http://www.zazzle.com/MathematicalOrchid*
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
|
|