|
 |
On 4/23/2011 4:15, Orchid XP v8 wrote:
> Hint: Look up "darcs fetch". It fetches changes without applying them.
OK. It sounded to me like Darcs had one working copy and one repository, and
applying all the patches from the repository would give you a "pristine"
version, and the working version was differenced from the pristine version
to get the next patch.
So it sounds like you can't actually fetch changes without having them
actually be relevant to the working directory. If you make the WD match the
repository, then fetch changes without applying them, then ask for diffs,
isn't Darcs going to tell you the WD doesn't match the repository? If your
change added the line ABC, isn't darcs diff going to tell you you removed
ABC from the WD?
So what do you mean "apply"? What happens if your WD matches the
repository, then you do a fetch, then you say "record", what does Darcs do?
> It's the fact that you have to commit the merged version of the file as a
> new version. Every time you merge in a new change, you have to commit a new
> version. It just seems clunky and unecessary.
It's mildly clunky, but it tells you which changes are applied to which
snapshots. git does this because it records files, not changes, yes. It's
probably the part of git that people like least.
What happens if I have a number of tags in the repository (v1 and v2 and the
current v3 under development), and I want to apply a bugfix to the v1
version that doesn't apply to the later versions? How do I do that?
>> In Darcs, that's one step it seems - I can't get changes
>> from you *without* applying them to the work I'm doing.
>
> Not true. You can get changes without applying them. It's just that usually,
> you want to fetch changes to, you know, *use* them.
But if you have multiple branches, like V1, V2, and V3beta1, and someone
sends you a new feature for V3beta1, you don't want to apply that to V1 or
V2. If you get a bugfix for V1 and make V1.01 you might or might not want
to apply that to V3.
> Then why fetch the changes at all? Why not wait until you're actually ready
> to apply them?
Welcome to DVCS!
Plus, what do you mean "apply"? git stores multiple branches in one
repository. I could as easily ask you "why wouldn't you apply every change
you get to every copy of the Darcs repository for your program?" The answer
is "because maybe I don't want to change that repository."
I might want to push changes up to a shared repository so everyone in the
team can work on them, but I don't want it going into production or even to
people not on the team.
I might want the development branch to apply the changes but not the branch
that's half way thru QA testing.
>> So if you have something like Linux, where there's a new release every
>> few months, you need a complete repository for every release.
>
> Um... why?
Because you don't want all the changes applied to old versions of Linux?
Maybe Darcs tags would do the trick there?
>> And if I
>> fix a bug in an old release and you want to incorporate that bug fix
>> into newer releases, what do you do?
>
> Oh, I see. You mean if you actually have multiple versions of something
> being developed concurrently? Yeah, in that case you'd have to move the
> changeset from one branch to another and hope it works.
And *that* is exactly what a git merge is. You don't do a merge every time
you record a change. You only do a merge when you're actually, you know,
merging two sets of changes into one branch of the repository.
A git branch is like a darcs repository.
A git commit is like a darcs record.
A git merge is like a darcs fetch-and-apply.
>>> You then have to
>>> *create a new commit object* representing this new combined state.
>>
>> Yes.
>
> So if two people have the same repo, and they merge in change X and then
> later merge in change Y, and then the other guy merges in change Y first and
> later change X, they now apparently have conflicting histories.
Well, you don't really "merge in" a change. You merge a change from one
branch to another. You're not merging changes, you're merging branches.
You're not going to have conflicting histories. Indeed, you *can't* have
conflicting histories because history is immutable. You might have different
histories in each repository, but that's like having two Darcs repositories
cloned from the same source but with a different set of changes in each.
So if we start at the same version, and you make three changes, and I make
three changes, and assuming there's no conflicts, when I merge your changes
into mine, I'll get the same files as if you merged my changes into yours,
so we'll both wind up with the same files, except yours will say yours
committed it and mine will say mine committed it.
Normally the only reason you'd both merge in the other person's changes is
if you're both going to keep developing on your own. Otherwise, what you
ought to do is I merge in your changes, and then give you the result to
continue from.
Obviously it's not a problem if you don't later combine the repositories
into one history. If you do, then you'll have two branches, and your pointer
will point to yours, and mine will point to mine, and they'll each be
pointing to a separate commit with the same files in each one (assuming
they're identical contents and that you didn't resolve merge conflicts
differently than I did).
> (And all
> because Git wants to pretend that everything happens in linear order.)
No, git very specifically does *not* pretend things happen in a linear
order. There's all kinds of tools to examine the DAG of dependencies
between versions.
> How do you get out of that?
If it comes time to turn your work and my work into the same branch, you
just merge the two branches in both repositories and work from there on,
which won't cause any merge conflicts because they're all the same files.
It's a DAG.
It would be similar in Darcs as if I set a tag in my repo and you set one in
your repo, then we merged them, and now you ask "how do you make a tag that
incorporates all the changes?" Well, if I took your changeset and you took
my change set, we'd have two tags. Make a third tag that points to the
combined set.
> As I say, it just annoys me that you have to assign an arbitrary ordering to
> changes.
It's not really arbitrary. Darcs just ignores the fact that they aren't.
If I add function AAA to file BBB and record that change, then add a call to
function AAA into file CCC, then record that change, would that really be
independent unordered changes in Darcs? That seems awfully fragile.
>> Say you have 25 changes in your Darcs repository, and you want a version
>> that applies every change except #23. What do you put in the repository
>> to represent that?
>
> You ask Darcs to revert change #23.
And how do you do that? "darcs revert" doesn't do that. "darcs unrecord"
throws the change away entirely. Obliterate deletes the patch entirely as well.
So it sounds like the actual answer is "you have to clone the entire
repository, then you have to obliterate the patch, and then you have to
rebuild the working directory from the new repository, and *then* you're
done, yes?
>>> It also irritates me that Git insists that even unrelated changes must
>>> have a linear time ordering.
>>
>> No they don't. Indeed, if unrelated changes had to have a linear time
>> ordering, you wouldn't get merge conflicts at all, would you?
>
> This doesn't make any sense to me at all...
Patches within any one branch have a linear time ordering. But git handles
multiple branches in the same repository. So changes between branches aren't
linearly ordered.
If changes were all linearly ordered, you'd never have to resolve merges,
because you could never have two independent patches trying to be applied to
the same place in the file, because one would definitely come before the
other, right?
Even on the same branch, while the changes are recorded linearly, if there
aren't conflicts between them, it's trivial to rearrange the order however
you want. Just like in Darcs you can't rearrange a patch that deletes a line
to be applied earlier than the patch that creates the line, so there's a
partial ordering in Darcs also. Same in git - it's a DAG with a partial
ordering. It's not linear.
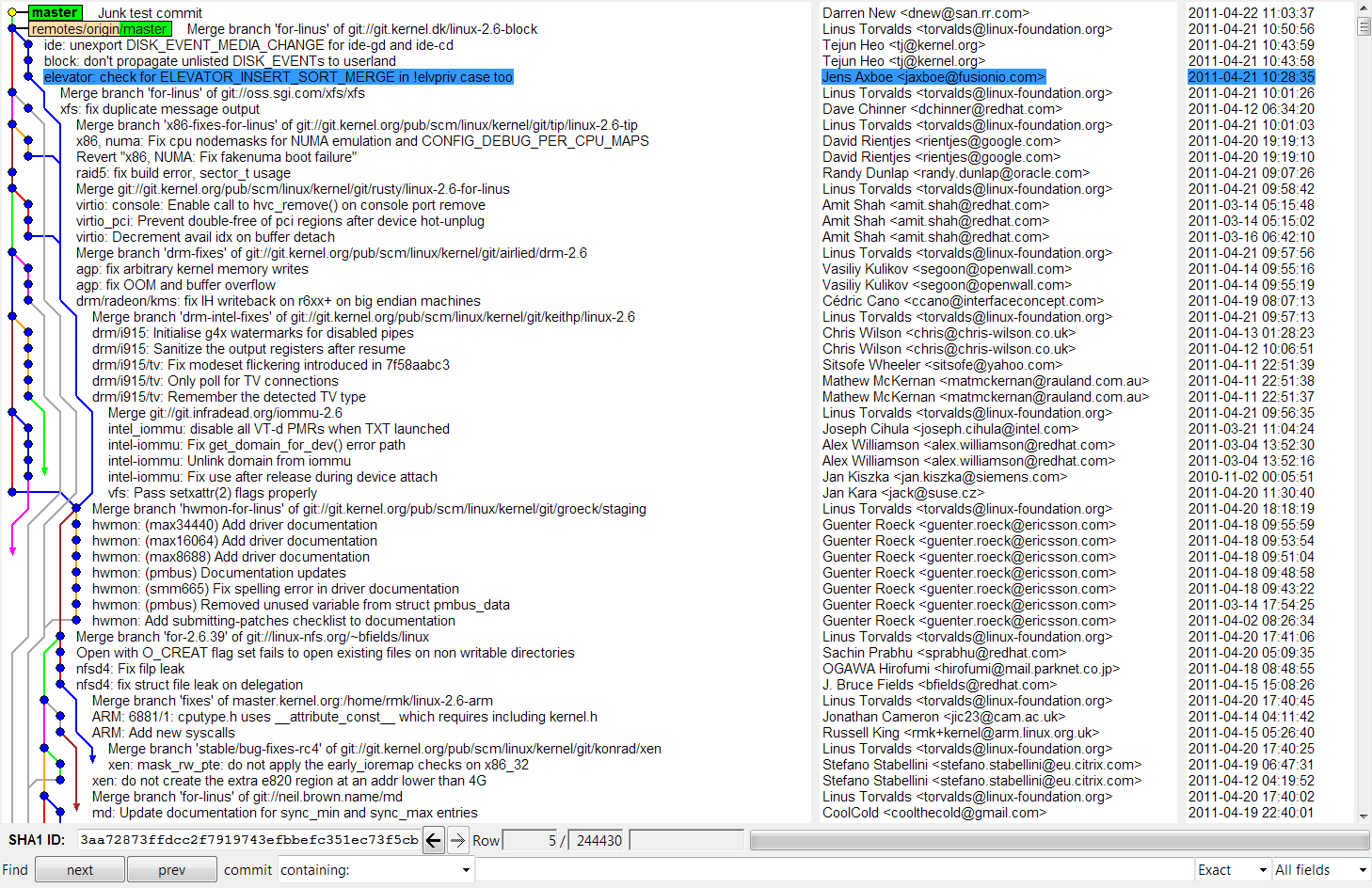
For example, attached is a picture of the last few dozen commits to the
Linux kernel.
--
Darren New, San Diego CA, USA (PST)
"Coding without comments is like
driving without turn signals."
Post a reply to this message
Attachments:
Download 'image1.png' (172 KB)
Preview of image 'image1.png'
|
|