|
|
|
|
|
|
| |
| |
|
|
|
|
| |
| |
|
|
I have taken a look at Friedrich Lohmueller's examples for using utf8
characters, however I am having a hard time understanding exactly how all of the
font/typeface files are structured and how to induce POV-Ray to render the
desired glyphs.
Take for example:
https://machinistguides.com/free-geometric-dimensioning-and-tolerancing-font-gdt-keyboard-shortcuts/
I have tried using "\u25B1" and similar hexadecimal values to try to display the
symbols. All I get is that "default unprintable character" box glyph .
I'm not sure about the ALT-#### characters - maybe those are "extended ACII" an
I just use chr (####)? But I still the "The Box".
Linux font viewer shows me the usual Quick Brown Fox stuff, and "Character Map"
shows me a gazillion symbols all the way up to "U+10FFFF"
But I have no idea how to decipher a way to display them.
Also, when using
global_settings {charset utf8 assumed_gamma 1.0}
I get:
Parse Warning: Encountered 'charset' global setting. As of POV-Ray v3.8, this
mechanism of specifying character encoding is no longer supported, and future
versions may treat the presence of the setting as an error.
So, if anyone has any information on what I ought to be doing, that would be
great :)
Thanks.
Post a reply to this message
|
|
| |
| |
|
|
From: clipka
Subject: Re: Requesting a more comprehensive text {} usage tutorial - utf8, ALT-####, et=
Date: 6 Jul 2021 21:11:49
Message: <60e4ff55@news.povray.org>
|
|
|
| |
| |
|
|
Am 06.07.2021 um 21:58 schrieb Bald Eagle:
> So, if anyone has any information on what I ought to be doing, that would be
> great :)
Did I ever mention that handling of character encoding in POV-Ray v3.7
is seriously borked?
And the decision was made to retain this borkedness in v3.8, for the
sake of backward compatibility.
And you shouldn't be using v3.8.0-10008988 or later, as most of the
changes they have brought will _not_ make it into v3.8.0 proper.
Particularly not any changes regarding character encoding.
Oh, and in case you're trying this with the "ANSI_GDT" font, version
1.0, from 1998: That one also seems to be borked, and is not helping.
As for the character codes given on that web page:
- The Alt+X codes _should_ directly translate to `\uXXXX` codes.
Provided the borkedness of POV-Ray's TrueType handling doesn't get in
the way, and `charset` is set to `utf8` or `sys`.
- Alt-codes starting with "0" _should_ directly translate to `chr(n)`.
Again provided the borkedness of POV-Ray's TrueType handling doesn't get
in the way.
- For other Alt-codes there is _some_ mapping, but it is far from
trivial, and is related to old DOS-era character codes. And again, it is
subject to borkedness and possibly `charset`.
- Some of those codes may only be valid for that particular font.
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
Did I ever mention that handling of character encoding in POV-Ray v3.7
is seriously borked?
.. . . maaaaaaaaayyyyyyyybe.
And the decision was made to retain this borkedness in v3.8, for the
sake of backward compatibility.
you - - - might have mentioned that at some point.
And you shouldn't be using v3.8.0-10008988 or later, as most of the
changes they have brought will _not_ make it into v3.8.0 proper.
Particularly not any changes regarding character encoding.
I use Dick Balaska's qtpovray, much to jr's consternation. I have way too much
going on right now to go rearranging my "workflow". Maybe this Fall.
Oh, and in case you're trying this with the "ANSI_GDT" font, version
1.0, from 1998: That one also seems to be borked, and is not helping.
No idea.
I tried with the 3 shipped fonts, and then moved on.
As for the character codes given on that web page:
- The Alt+X codes _should_ directly translate to `\uXXXX` codes.
Provided the borkedness of POV-Ray's TrueType handling doesn't get in
the way, and `charset` is set to `utf8` or `sys`.
They do not. But I found a page that provides a mapping.
- Alt-codes starting with "0" _should_ directly translate to `chr(n)`.
Again provided the borkedness of POV-Ray's TrueType handling doesn't get
in the way.
Maybe yes, maybe no. It gets weird.
- For other Alt-codes there is _some_ mapping, but it is far from
trivial, and is related to old DOS-era character codes. And again, it is
subject to borkedness and possibly `charset`.
Yes, I saw some notes to that effect.
- Some of those codes may only be valid for that particular font.
Right.
So just for anyone else looking to dabble with any of this, this is what I
found:
"We are the Bork. You will be dissimilated, and your assstinktiveness will be
retained in the source code."
Aside from that, the "Character Map" (charmap) is a POS. Confusing and not very
helpful.
I downloaded FontForge and that seems to work very nicely.
What that will tell you is that lots of fonts don't have very much content - and
there are tons of unicode entries "left blank". FontForge will show you the map
entry, what ought to be there if a glyph has been constructed, and whether it
exists or not. It will also give you information about any faults and errors
in the font file, such as incorrect mappings.
After researching a bit more and searching for a "more complete" unicode font, I
found:
lucida-sans-unicode.ttf is a fairly complete font for these purposes, but better
is:
arial-unicode-ms.ttf Which has quite a lot of the goodies.
I would recommmend that anyone desiring to make use of symbols download these
fonts and put them in their include file path.
It not only has the symbols that I was looking for here, but all of the math
symbols, and plenty of arrow and other symbols that would be useful as a quick
way of drawing those without a macro and a bunch of 3D primitives.
https://allfont.net/download/lucida-sans-unicode/#download
https://ufonts.com/downloads/197925!474209627
So yes, the fundamental issue is that most fonts are crap, or at least woefully
sparse.
.... Unless P J O'Rork from York horked a cork with a fork and porked Mork from
Ork like a dork (or that Ferengi Quark) while playing Zork, thereby screwing up
the character map encoding . . . but absent that, the character mapping for the
\uNNNN codes seems to be fairly reliable and consistent across the handful of
fonts I sifted through.
Other than that, POV-Ray seems to have handled everything fairly nicely. Some
of the glyphs are a wee bit spindly, but that's the font, not POV-Ray. I just
deleted the whole charset and utf8, and so now there's no parse warning, and
everything works great anyway.
:D
Post a reply to this message
|
|
| |
| |
|
|
From: clipka
Subject: Re: Requesting a more comprehensive text {} usage tutorial - utf8, ALT-####=
Date: 7 Jul 2021 05:29:12
Message: <60e573e8$1@news.povray.org>
|
|
|
| |
| |
|
|
Am 07.07.2021 um 04:06 schrieb Bald Eagle:
> Oh, and in case you're trying this with the "ANSI_GDT" font, version
> 1.0, from 1998: That one also seems to be borked, and is not helping.
>
> No idea.
> I tried with the 3 shipped fonts, and then moved on.
You mean the fonts that come with POV-Ray?
Noooooooo - they don't have much in terms of support for non-ASCII
characters at all, let alone Unicode.
> As for the character codes given on that web page:
>
> - The Alt+X codes _should_ directly translate to `\uXXXX` codes.
> Provided the borkedness of POV-Ray's TrueType handling doesn't get in
> the way, and `charset` is set to `utf8` or `sys`.
>
> They do not. But I found a page that provides a mapping.
?? - That's quite a surprise there. The Alt+X input method in Word
(4-digit/letter hexadecimal code followed by Alt+X) is _specifically_
designed to enter Unicode codepoints using hexadecimal notation, and
`\uXXXX` is _specifically_ designed to specify Unicode codepoints using
hexadecimal notation. If they deviate, something is wrong.
(At least for 4-digit/character codes. Those with more digits/letters
are another matter.)
> "We are the Bork. You will be dissimilated, and your assstinktiveness will be
> retained in the source code."
For v3.8, yes.
For later versions (which we've decided to call v4.0, while postponing
other more radical renewals for some v5.0), things will be cleaned up.
> I downloaded FontForge and that seems to work very nicely.
>
> What that will tell you is that lots of fonts don't have very much content - and
> there are tons of unicode entries "left blank".
No surprise there. Providing glyphs for all Unicode codepoints defined
so far would be a ton of work (remember, you'd want to define all of
them in the same style; and you'd need to know at least some basics
about the typography of each and every script in the world to get it
right; for example, a lot of fonts get the Euro sign typographically
wrong, and the fonts that provide an uppercase variant of the German
sz-ligature often get that one wrong as well) and also require tons of
storage space. So fonts typically cater to a particular set of
languages, and leave all others empty.
Software that does a lot of text displaying (most notably browsers)
solve this problem by using a system of fallback fonts (none of which
cover all of Unicode individually, but in total they do) to display
characters that aren't available in the primary font of a web page.
> lucida-sans-unicode.ttf is a fairly complete font for these purposes, but better
> is:
>
> arial-unicode-ms.ttf Which has quite a lot of the goodies.
Yes, those two fonts are my go-to as well when it comes to
"Unicode-richness".
> . . . but absent that, the character mapping for the
> \uNNNN codes seems to be fairly reliable and consistent across the handful of
> fonts I sifted through.
>
> Other than that, POV-Ray seems to have handled everything fairly nicely. Some
> of the glyphs are a wee bit spindly, but that's the font, not POV-Ray. I just
> deleted the whole charset and utf8, and so now there's no parse warning, and
> everything works great anyway.
There are scenarios though where perfectly valid fonts would end up
garbled by POV-Ray. Fortunately they seem to be rare with high-quality
fonts.
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
clipka <ano### [at] anonymous org> wrote:
> Noooooooo - they don't have much in terms of support for non-ASCII
> characters at all, let alone Unicode.
Yesssssssssssssss - because I haven't dissected and designed fonts since I was
doing it in 8-bit bitmap fonts on a VIC-20.... :P
> ?? - That's quite a surprise there. The Alt+X input method in Word
> (4-digit/letter hexadecimal code followed by Alt+X) is _specifically_
> designed to enter Unicode codepoints using hexadecimal notation, and
> `\uXXXX` is _specifically_ designed to specify Unicode codepoints using
> hexadecimal notation. If they deviate, something is wrong.
>
> (At least for 4-digit/character codes. Those with more digits/letters
> are another matter.)
Well, all I can say is that plug-and-chug with the "let me just use the \u
method to implement the ALT-NNNN notation" didn't work.
Here's the site which has those and other codepoints.
https://altcodeunicode.com/alt-codes-miscellaneous-technical-symbols/
It didn't make any sense to me that they were different, except for the fact
that the original article recommended 2 different ways to invoke those glyphs -
if the unicode method worked like that, then why even mention the ALT method.
Unless of course some are in decimal and the others are in hex (or oct)
(Can the alt-method be used with hex???)
> No surprise there. Providing glyphs for all Unicode codepoints defined
> so far would be a ton of work (remember, you'd want to define all of
> them in the same style; and you'd need to know at least some basics
> about the typography of each and every script in the world to get it
> right; for example, a lot of fonts get the Euro sign typographically
> wrong, and the fonts that provide an uppercase variant of the German
> sz-ligature often get that one wrong as well) and also require tons of
> storage space. So fonts typically cater to a particular set of
> languages, and leave all others empty.
Yes, "Noto" fonts and "code2000" were referenced in my readings, as well the
fact that there's SO much information covered by the unicode standard that you
can't fit it all into a single font file, and it has to be split.
> Software that does a lot of text displaying (most notably browsers)
> solve this problem by using a system of fallback fonts (none of which
> cover all of Unicode individually, but in total they do) to display
> characters that aren't available in the primary font of a web page.
Maybe for 4.0 or 5.0, text {} could take a _list_ of fonts, and start with the
first entry, to do a similar thing.
Also maybe a font-freak would decide that creating a (few) custom font(s) for
POV-Ray would be a great project... ;)
> There are scenarios though where perfectly valid fonts would end up
> garbled by POV-Ray. Fortunately they seem to be rare with high-quality
> fonts.
We work with what we have, right? And for the moment, everything that I need is
moving along, so I will consider that and some additional learning under my belt
to be a win. :) org> wrote:
> Noooooooo - they don't have much in terms of support for non-ASCII
> characters at all, let alone Unicode.
Yesssssssssssssss - because I haven't dissected and designed fonts since I was
doing it in 8-bit bitmap fonts on a VIC-20.... :P
> ?? - That's quite a surprise there. The Alt+X input method in Word
> (4-digit/letter hexadecimal code followed by Alt+X) is _specifically_
> designed to enter Unicode codepoints using hexadecimal notation, and
> `\uXXXX` is _specifically_ designed to specify Unicode codepoints using
> hexadecimal notation. If they deviate, something is wrong.
>
> (At least for 4-digit/character codes. Those with more digits/letters
> are another matter.)
Well, all I can say is that plug-and-chug with the "let me just use the \u
method to implement the ALT-NNNN notation" didn't work.
Here's the site which has those and other codepoints.
https://altcodeunicode.com/alt-codes-miscellaneous-technical-symbols/
It didn't make any sense to me that they were different, except for the fact
that the original article recommended 2 different ways to invoke those glyphs -
if the unicode method worked like that, then why even mention the ALT method.
Unless of course some are in decimal and the others are in hex (or oct)
(Can the alt-method be used with hex???)
> No surprise there. Providing glyphs for all Unicode codepoints defined
> so far would be a ton of work (remember, you'd want to define all of
> them in the same style; and you'd need to know at least some basics
> about the typography of each and every script in the world to get it
> right; for example, a lot of fonts get the Euro sign typographically
> wrong, and the fonts that provide an uppercase variant of the German
> sz-ligature often get that one wrong as well) and also require tons of
> storage space. So fonts typically cater to a particular set of
> languages, and leave all others empty.
Yes, "Noto" fonts and "code2000" were referenced in my readings, as well the
fact that there's SO much information covered by the unicode standard that you
can't fit it all into a single font file, and it has to be split.
> Software that does a lot of text displaying (most notably browsers)
> solve this problem by using a system of fallback fonts (none of which
> cover all of Unicode individually, but in total they do) to display
> characters that aren't available in the primary font of a web page.
Maybe for 4.0 or 5.0, text {} could take a _list_ of fonts, and start with the
first entry, to do a similar thing.
Also maybe a font-freak would decide that creating a (few) custom font(s) for
POV-Ray would be a great project... ;)
> There are scenarios though where perfectly valid fonts would end up
> garbled by POV-Ray. Fortunately they seem to be rare with high-quality
> fonts.
We work with what we have, right? And for the moment, everything that I need is
moving along, so I will consider that and some additional learning under my belt
to be a win. :)
Post a reply to this message
|
|
| |
| |
|
|
From: clipka
Subject: Re: Requesting a more comprehensive text {} usage tutorial - utf8, ALT-####=
Date: 7 Jul 2021 07:48:51
Message: <60e594a3$1@news.povray.org>
|
|
|
| |
| |
|
|
Am 07.07.2021 um 12:28 schrieb Bald Eagle:
>> ?? - That's quite a surprise there. The Alt+X input method in Word
>> (4-digit/letter hexadecimal code followed by Alt+X) is _specifically_
>> designed to enter Unicode codepoints using hexadecimal notation, and
>> `\uXXXX` is _specifically_ designed to specify Unicode codepoints using
>> hexadecimal notation. If they deviate, something is wrong.
>>
>> (At least for 4-digit/character codes. Those with more digits/letters
>> are another matter.)
>
> Well, all I can say is that plug-and-chug with the "let me just use the \u
> method to implement the ALT-NNNN notation" didn't work.
> Here's the site which has those and other codepoints.
> https://altcodeunicode.com/alt-codes-miscellaneous-technical-symbols/
Ah, no - that's not what I meant. What I was talking about are the "NNNN
Alt+X" codes.
As for the 4-digit "Alt+NNNN" codes, they're just the decimal equivalent
of the `\uXXXX` hexadecimal codes.
Only the 3-or-fewer-digit codes are a genuine mess.
> It didn't make any sense to me that they were different, except for the fact
> that the original article recommended 2 different ways to invoke those glyphs -
> if the unicode method worked like that, then why even mention the ALT method.
The "ALT+NNNN" method has the advantage that it is a Windows feature
that works in all programs, but the disadvantage that it uses decimal
notation. The "NNNN Alt+X" method has the disadvantage that it is a
proprietary feature that only works in MS Word, but the advantage that
it uses hexadecimal notation.
The canonical notation to specify Unicode codepoints (i.e. character
codes, if you will) in human-readable free-form text is "U+NNNN", where
lower-case 'a' with grave accent). You rarely see Unicode codepoints
specified by their decimal value.
>> Software that does a lot of text displaying (most notably browsers)
>> solve this problem by using a system of fallback fonts (none of which
>> cover all of Unicode individually, but in total they do) to display
>> characters that aren't available in the primary font of a web page.
>
> Maybe for 4.0 or 5.0, text {} could take a _list_ of fonts, and start with the
> first entry, to do a similar thing.
I'd slap a "v4.1" label on that feature for now.
I'm also pondering a syntax to supply a list of custom objects to use as
a character set.
> Also maybe a font-freak would decide that creating a (few) custom font(s) for
> POV-Ray would be a great project... ;)
I don't know; in my book, v4.0 should bundle a handful of reasonably
good run-of-the-mill free fonts cobbled together from the internerds.
I'd argue for providing (1) a serif font, a sans-serif font and a
monospace font, each covering the entire Latin/Cyrillic/Greek family of
scripts; and (2) as many additional fonts as needed to cover the entire
Base Multilingual Plane (16-bit subset of Unicode).
There are so many free fonts out there that it would be ridiculous to
design yet another one from scratch. We'll also have OpenType fonts to
choose from, as v4.0 will definitely support those as well.
I also wouldn't go too fancy in terms of italics or boldface fonts, as I
expect v4.0 to provide means to auto-generate oblique and bold fonts
from regular ones, and also to provide easy access to fonts installed in
the system. (At least for Windows, the latter is a given.)
(What we _could_ do is create "watered-down" versions of existing fonts,
stripping away any hinting information, to save memory; we don't need
our fonts to be hinted, as we're not rasterizing them in the traditional
sense. But the fact that we could doesn't necessarily mean we should.)
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
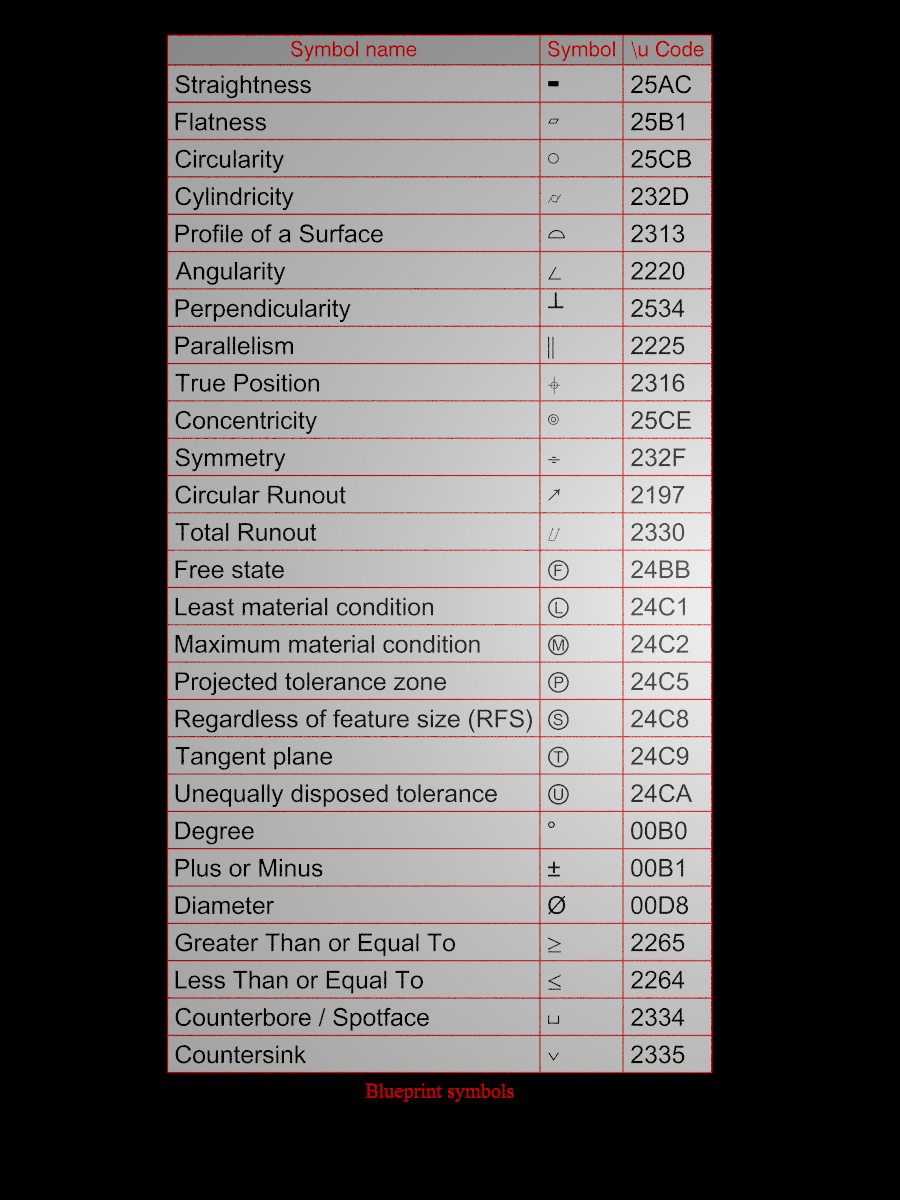
I've been reminded that I never posted the render of the solved problem, so here
are the goodies, rendered with jr's Tabulated () macro.
Post a reply to this message
Attachments:
Download 'blueprintsymbols.png' (299 KB)
Preview of image 'blueprintsymbols.png'

|
|
| |
| |
|
|
|
|
| |
|
|