|
|
|
|
|
|
| |
| |
|
|
|
|
| |
| |
|
|
So, I've had a few ideas that I've wanted to pursue, and for those, I need a few
tools to perform the tasks more rigorously than "by eye".
I looked at converting some Javascript code, but gave up on that,
https://jsxgraph.uni-bayreuth.de/wiki/index.php/Least-squares_circle_fitting
then found a semi-encouraging post,
https://www.codeproject.com/Questions/228108/Linear-least-squares-circle-fit-in-C-or-Cplusplus
and then found the original paper,
https://ir.canterbury.ac.nz/bitstream/handle/10092/11104/coope_report_no69_1992.pdf?sequence=1
which I thought I could puzzle out - the solution seemed tantalizingly close,
https://towardsdatascience.com/building-linear-regression-least-squares-with-linear-algebra-2adf071dd5dd
https://online.stat.psu.edu/stat462/node/132/
But good ole' Coope just used too many x's and changes of variables, and
sparsely described methods of getting from point A to point B.
Luckily, I found some "good" c++ code, and I was able to successfully convert
the Taubin algebraic solution before I left for work:
https://people.cas.uab.edu/~mosya/cl/CPPcircle.html
and then got back home and worked on the geometric Levenberg-Marquardt fit, only
to find that it's written with a host of ugly "goto" statements. :O :(
I somehow navigated a path to simulate that in SDL, code the few dependencies,
and fake or ignore the rest. Got stuck in an endless while loop somewhere when
I started whittling down the circle to an arc of pi*0.6, but fixed that, and...
Seems to be working well enough. So now I have a regular linear least squares
regression macro, and at least one set of (seemingly) fully functional circle
fitting macros.
Onwards we trudge....
Post a reply to this message
Attachments:
Download 'leastsquares_circle.png' (37 KB)
Preview of image 'leastsquares_circle.png'

|
|
| |
| |
|
|
|
|
| |
| |
|
|
On 11/03/2023 02:35, Bald Eagle wrote:
> Onwards we trudge....
Very interesting investigation !
I can imagine following application: we have volume, constrained by low-
poly mesh and want to fill it with spheres with radiuses from Rmin to
Rmax, achieving randomized, natural-like form. Using this method with
blobs can solve main blob-construction problem - low control and
accuracy.
--
YB
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
yesbird <sya### [at] gmail com> wrote:
> I can imagine following application: we have volume, constrained by low-
> poly mesh and want to fill it with spheres with radiuses from Rmin to
> Rmax, achieving randomized, natural-like form.
Well, that of course suggests that there's an analogous spherical method. I'll
have to look and see... com> wrote:
> I can imagine following application: we have volume, constrained by low-
> poly mesh and want to fill it with spheres with radiuses from Rmin to
> Rmax, achieving randomized, natural-like form.
Well, that of course suggests that there's an analogous spherical method. I'll
have to look and see...
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
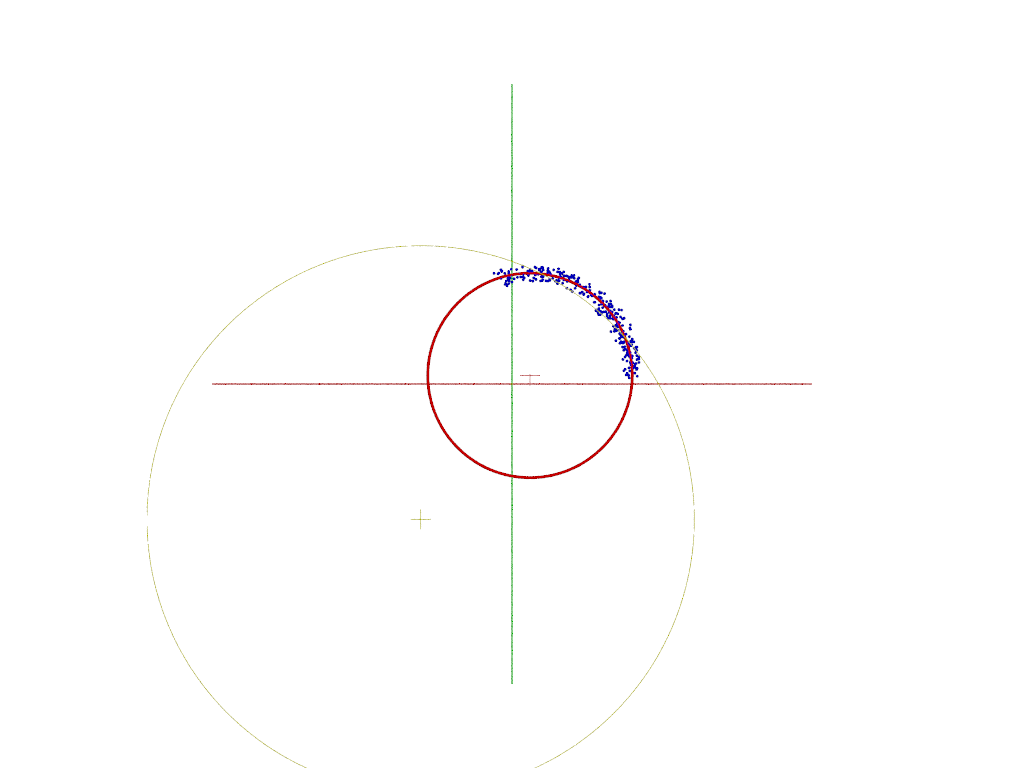
It occurred to me that I never described what the render shows.
The yellow circle shows the algebraic result when then data is restricted to a
small arc. (now WAY off) The red circle is the geometric result which gives a
much more accurate result, but requires an initial "guess" for the center and
radius - which the algebraic method provides.
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
"Bald Eagle" <cre### [at] netscapenet> wrote:
> yesbird <sya### [at] gmailcom> wrote:
>
> > I can imagine following application: we have volume, constrained by low-
> > poly mesh and want to fill it with spheres with radiuses from Rmin to
> > Rmax, achieving randomized, natural-like form.
>
> Well, that of course suggests that there's an analogous spherical method. I'll
> have to look and see...
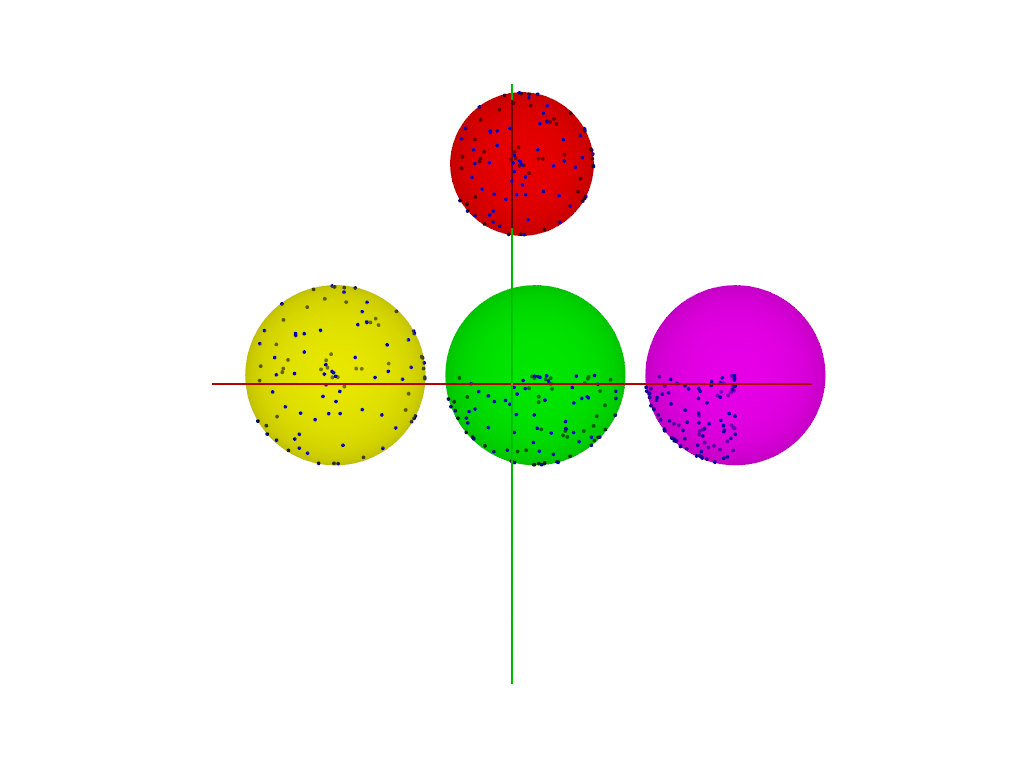
https://arxiv.org/ftp/arxiv/papers/1506/1506.02776.pdf
I have no idea where the crazy "sphere parametrization" equations come from, but
I used _normal_ equations, and fixed a typo in the last line of code (needs
-'s), and got that to work.
Render is the test data in the table of the paper.
Post a reply to this message
Attachments:
Download 'leastsquaressphere1.png' (59 KB)
Preview of image 'leastsquaressphere1.png'

|
|
| |
| |
|
|
|
|
| |
| |
|
|
"Bald Eagle" <cre### [at] netscapenet> wrote:
> https://arxiv.org/ftp/arxiv/papers/1506/1506.02776.pdf
> ...
> I have no idea where the crazy "sphere parametrization" equations come from, but
> I used _normal_ equations, and fixed a typo in the last line of code (needs
> -'s), and got that to work.
I'am afraid that this paper describes the opposite process: fitting something
_into_ sphere. I mean counctrusting arbitrary form _from_ spheres of different
radiuses to achieve best fit (most completed volume). Sorry for
misunderstanding.
Despite that, I forced this Matlab function to work, fixing a few typos.
In any case this was an interesting investigation, I suppose, we can use this
method in future for something useful.
--
YB
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
"yesbird" <nomail@nomail> wrote:
> I'am afraid that this paper describes the opposite process: fitting something
> _into_ sphere. I mean counctrusting arbitrary form _from_ spheres of different
> radiuses to achieve best fit (most completed volume). Sorry for
> misunderstanding.
I'm not sure how you reach that conclusion, since the function takes all of the
randomly generated points and calculates the center point and radius of a single
best-fitting sphere. It fits a sphere to the data, not the other way around.
> Despite that, I forced this Matlab function to work, fixing a few typos.
Excellent. Maybe Matlab can process mesh vertices / point clouds too?
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
That's a really nice result of fitting a set of data points to a function. But
I wish I understood what all of this was about-- starting with the fundamental
idea of the 'sum of least SQUARES' and why 'squaring' the residual data errors
is used in these techniques. I don't remember ever being introduced to that
concept, in either high-school or college maths classes. (But, I never took a
course in statistics.) The various internet articles on the subject that I have
read over the years are woefully complex and do not explain the *why* of it.
From the Wikipedia article "Partition of sums of squares":
"The distance from any point in a collection of data, to the mean of the data,
is the deviation. ...If all such deviations are squared, then summed, as in
[equation], this gives the "sum of squares" for these data."
The general idea of finding the AVERAGE of a set of data points is easy enough
to understand, as is finding the deviations or 'offsets' of those points from
the average. But why is 'squaring' then used? What does that actually
accomplish? I have not yet found a simple explanation.
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
"Kenneth" <kdw### [at] gmailcom> wrote:
> That's a really nice result of fitting a set of data points to a function.
It's the reverse. I'm fitting the function describing a line, circle, and
sphere to the measured data. It's "as close to all of the data points as it can
be _simultaneously_". And so the overall error is minimized.
> But
> I wish I understood what all of this was about-- starting with the fundamental
> idea of the 'sum of least SQUARES' and why 'squaring' the residual data errors
> is used in these techniques.
I never did much in those areas either. And to be honest, it's "dangerous" to
be doing serious work with measured values and not understand the basics of the
statistics. When I worked at American Cyanamid, they had a statistician come in
and give a presentation - in which he showed like 8 sets of data that all had
the same standard deviation, and all looked completely different.
> The general idea of finding the AVERAGE of a set of data points is easy enough
> to understand, as is finding the deviations or 'offsets' of those points from
> the average.
This is an acceptable method, and of course can be found in early treatments of
computing the errors in data sets.
> But why is 'squaring' then used? What does that actually
> accomplish? I have not yet found a simple explanation.
"it makes some of the math simpler" especially when doing multiple dimension
analyses.
(the variance is equal to the expected value of the square of the distribution
minus the square of the mean of the distribution)
You're also doing a sort of Pythagorean/Euclidean distance calculation, and
that's done with squares rather than absolute values.
"Variances are additive for independent random variables"
"Say I toss a fair coin 900 times. What's the probability that the number of
heads I get is between 440 and 455 inclusive? Just find the expected number of
heads (450 ), and the variance of the number of heads (225=152
), then find the probability with a normal (or Gaussian) distribution with
expectation 450 and standard deviation 15 is between 439.5 and 455.5."
"while the absolute value function (unsquared) is continuous everywhere, its
first derivative is not (at x=0). This makes analytical optimization more
difficult"
https://stats.stackexchange.com/questions/118/why-square-the-difference-instead-of-taking-the-absolute-value-in-standar
d-devia
https://stats.stackexchange.com/questions/46019/why-squared-residuals-instead-of-absolute-residuals-in-ols-estimation
"A lot of reasons."
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
"Bald Eagle" <cre### [at] netscapenet> wrote:
> "Kenneth" <kdw### [at] gmailcom> wrote:
> > That's a really nice result of fitting a set of data points to a function.
>
> It's the reverse. I'm fitting the function describing a line, circle, and
> sphere to the measured data. It's "as close to all of the data points as
> it can be _simultaneously_". And so the overall error is minimized.
Got it. Sorry for my reversed and lazy way of describing things.
> > The general idea of finding the AVERAGE of a set of data points is
> > easy enough to understand...
>
> This is an acceptable method, and of course can be found in early
> treatments of computing the errors in data sets.
>
> > But why is 'squaring' then used? What does that actually
> > accomplish? I have not yet found a simple explanation.
>
> "it makes some of the math simpler" especially when doing multiple dimension
> analyses.
>
> (the variance is equal to the expected value of the square of the distribution
> minus the square of the mean of the distribution)
>
So the (naive) question that I've always pondered is, would CUBING the
appropriate values-- instead of squaring them-- produce an even tighter fit
between function and data points? (Assuming that I understand anything at all
about why even 'squaring' is the accepted method, ha.) Although, I imagine that
squaring is perhaps 'good enough', and that cubing would be an unnecessary and
more complex mathematical step.
From reading at least various Wikipedia pages re: the discovery or invention of
'sum of squares' etc, it kind of gives me the impression that Gauss et al came
up with the method in an empirical way(?) rather than from any theoretical
standpoint. And that it simply proved useful.
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |