|
|
|
|
|
|
| |
| |
|
|
|
|
| |
| |
|
|
I'm well aware that there are complaints about speed, and the topics of parallel
processing and gpu have been addressed.
I'm also aware that SDL is not a compiled language.
This is a legitimate inquiry (sprinkled with White whine) to further educate
myself and the non-POV-team/developer community.
Just for my own information, I'm wondering why POV-Ray is so painfully slow to
process non-rendering information (parse time).
I'm asking, because I converted some of Paul Nylander's Mathematica code for the
reaction-diffusion algorithm to SDL, and although I knew beforehand that it has
a fair amount of looping through a 'large' array (160x120), I was still somewhat
amazed and dismayed that it was as slow as it was.
This is thrown into even starker contrast when I run the reaction-diffusion code
from Coding Challenge into Processing - which somehow manages to crank out
results on a 700 x 500 grid at 60 frames per second (that's what's in the code,
and the default speed - no idea if this is actual)
I'm pretty sure Processing is as high a level language as SDL, and it's not
compiled... so what IS the difference?
Is there some sort of bottleneck or fundamental reason that the programmatic
handling of data is so slow in comparison to other languages?
Thanks
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
Le 21/04/2018 à 17:03, Bald Eagle a écrit :
> I'm well aware that there are complaints about speed, and the topics of parallel
> processing and gpu have been addressed.
> I'm also aware that SDL is not a compiled language.
> This is a legitimate inquiry (sprinkled with White whine) to further educate
> myself and the non-POV-team/developer community.
>
>
>
> Just for my own information, I'm wondering why POV-Ray is so painfully slow to
> process non-rendering information (parse time).
>
> I'm asking, because I converted some of Paul Nylander's Mathematica code for the
> reaction-diffusion algorithm to SDL, and although I knew beforehand that it has
> a fair amount of looping through a 'large' array (160x120), I was still somewhat
> amazed and dismayed that it was as slow as it was.
>
> This is thrown into even starker contrast when I run the reaction-diffusion code
> from Coding Challenge into Processing - which somehow manages to crank out
> results on a 700 x 500 grid at 60 frames per second (that's what's in the code,
> and the default speed - no idea if this is actual)
> I'm pretty sure Processing is as high a level language as SDL, and it's not
> compiled... so what IS the difference?
>
> Is there some sort of bottleneck or fundamental reason that the programmatic
> handling of data is so slow in comparison to other languages?
>
> Thanks
1. I do not know.
2. I'm ready to help, I already have a debug version (with symbols in
code) of povray and a profiling tool that does not slow down too much
(not valgrind)
3. Please provide a scene that you find slow to parse (it must be
possible to render it, please, so that I get something to see, it does
not have to be nice)
Combining 2 & 3, we might get some insight.
This is a time limited offer.
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
:)
Thanks Jerome, Here's what I was just playing with.
http://news.povray.org/povray.text.scene-files/message/%3Cweb.5adb7bb992937f825cafe28e0%40news.povray.org%3E/#%3Cweb.5a
db7bb992937f825cafe28e0%40news.povray.org%3E
you can change the amount of processing required by using a different image
size, changing the "test" variable (test=10 = 1/10th of the area processed)
or changing the #for (DO, 1, ...) loop in line 48.
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
Le 21/04/2018 à 20:03, Bald Eagle a écrit :
> :)
> Thanks Jerome, Here's what I was just playing with.
>
>
>
http://news.povray.org/povray.text.scene-files/message/%3Cweb.5adb7bb992937f825cafe28e0%40news.povray.org%3E/#%3Cweb.5a
> db7bb992937f825cafe28e0%40news.povray.org%3E
>
> you can change the amount of processing required by using a different image
> size, changing the "test" variable (test=10 = 1/10th of the area processed)
> or changing the #for (DO, 1, ...) loop in line 48.
>
>
>
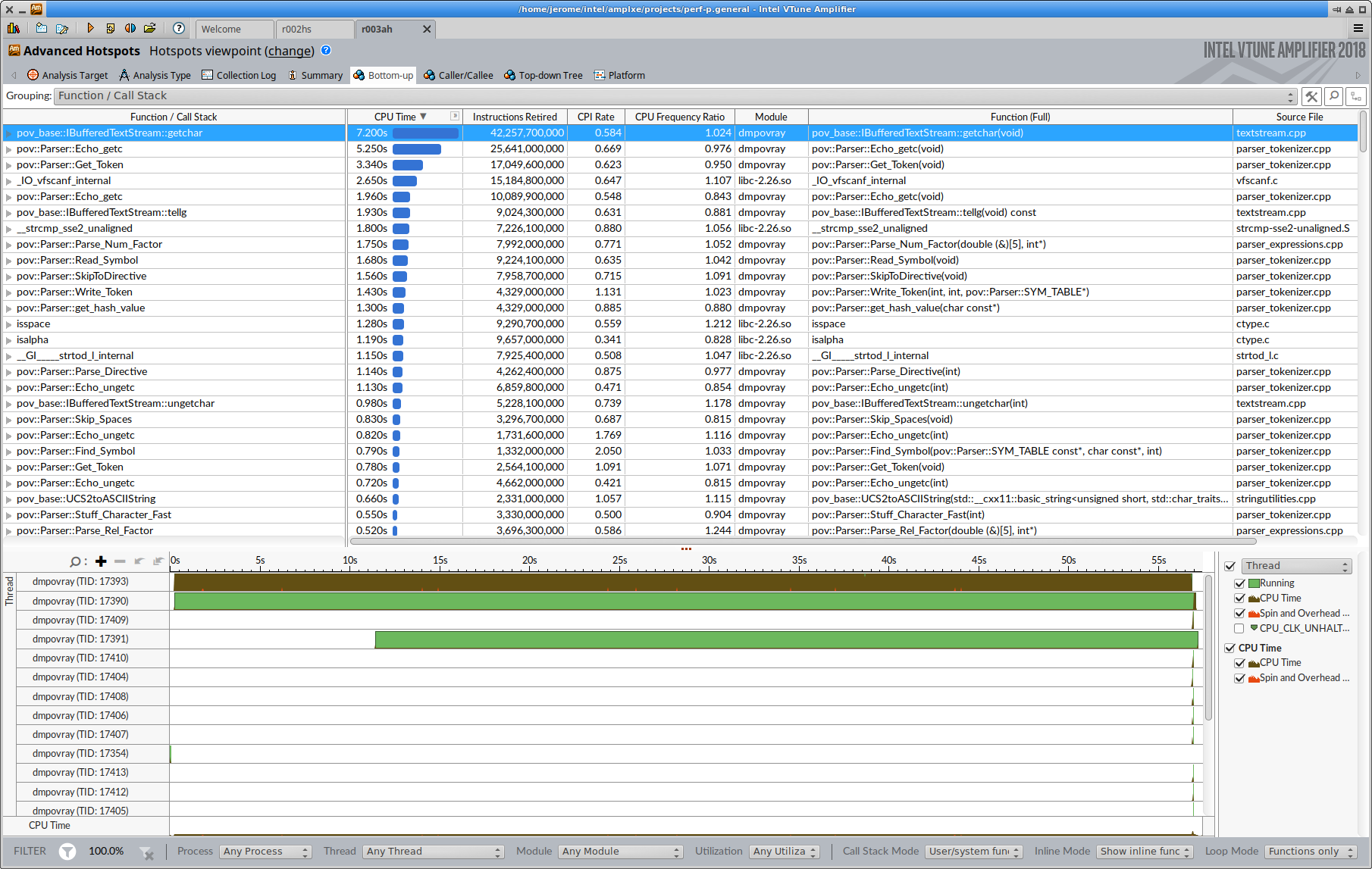
I tested with test=30 (to get a quick result, so less loops)
with a 800x600 image.
Parsing 314595K tokens
> Parser Time
> Parse Time: 0 hours 0 minutes 55 seconds (55.865 seconds)
> using 1 thread(s) with 55.849 CPU-seconds total
> Bounding Time: 0 hours 0 minutes 0 seconds (0.022 seconds)
> using 1 thread(s) with 0.018 CPU-seconds total
Now to dive into the code and try to understand.
The scanf is to parse each float (aka number), hard to optimize it.
Post a reply to this message
Attachments:
Download 'profile_parse_sdl.png' (335 KB)
Download 'profile_advanced.png' (320 KB)
Preview of image 'profile_parse_sdl.png'
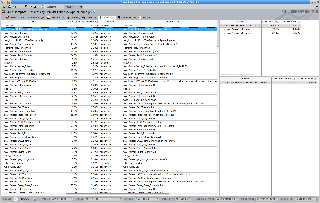
Preview of image 'profile_advanced.png'
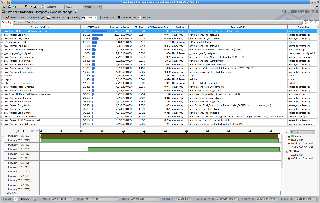
|
|
| |
| |
|
|
|
|
| |
| |
|
|
Le 18-04-21 à 11:03, Bald Eagle a écrit :
> I'm well aware that there are complaints about speed, and the topics of parallel
> processing and gpu have been addressed.
> I'm also aware that SDL is not a compiled language.
> This is a legitimate inquiry (sprinkled with White whine) to further educate
> myself and the non-POV-team/developer community.
>
>
>
> Just for my own information, I'm wondering why POV-Ray is so painfully slow to
> process non-rendering information (parse time).
>
> I'm asking, because I converted some of Paul Nylander's Mathematica code for the
> reaction-diffusion algorithm to SDL, and although I knew beforehand that it has
> a fair amount of looping through a 'large' array (160x120), I was still somewhat
> amazed and dismayed that it was as slow as it was.
>
> This is thrown into even starker contrast when I run the reaction-diffusion code
> from Coding Challenge into Processing - which somehow manages to crank out
> results on a 700 x 500 grid at 60 frames per second (that's what's in the code,
> and the default speed - no idea if this is actual)
> I'm pretty sure Processing is as high a level language as SDL, and it's not
> compiled... so what IS the difference?
>
> Is there some sort of bottleneck or fundamental reason that the programmatic
> handling of data is so slow in comparison to other languages?
>
> Thanks
>
>
Parsing is strictly iterative and can only use a single thread.
If you use any macro in a loop, it will get expanded and parsed each
time it's used.
If that macro is in an include file, that file will get opened and read
each time the macro is invoked. EVERYTHING before the macro definition
need to be read and skipped. Example : If you use any colour
manipulation macro from colors.inc, they are located at the end, forcing
the parser to read the whole include every time they are used. It get
much worse if a macro also use another macro from another include...
Cure : Copy any macro that is used in a loop into your main file. Remove
any comment located within the macro, or move them before the macro
definition.
It takes time to skip over comments : The parser need to read each
character until it find the next non-comment one. Try to place your
comments out of any loops, especially the inner loops when you have
nested loops.
Long variables names are nice to make your code understandable and easy
to maintain, but take longer to parse. In any loop, use short names
making sure that they are properly commented/explained out of the loop.
The gain is small, but quickly add up in a loop.
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
On 04/21/2018 03:30 PM, Alain wrote:
> Example : If you use any colour
> manipulation macro from colors.inc, they are located at the end, forcing
> the parser to read the whole include every time they are used.
I don't think that's true. When first encountered, the parser makes
note of the location. When the macro is used, it does have to reopen
colors.inc and fseek to the position of the macro.
clipka mentioned something like "macros less than 64KB are now cached".
Not sure which version that applies to.
--
dik
Rendered 328976 of 330000 (99%)
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
Alain <kua### [at] videotron ca> wrote:
>
> Parsing is strictly iterative and can only use a single thread.
>
> If you use any macro in a loop, it will get expanded and parsed each
> time it's used.
>
> If that macro is in an include file, that file will get opened and read
> each time the macro is invoked. EVERYTHING before the macro definition
> need to be read and skipped. Example : If you use any colour
> manipulation macro from colors.inc, they are located at the end, forcing
> the parser to read the whole include every time they are used...
> Cure : Copy any macro that is used in a loop into
> your main file. Remove any comment located within the macro, or move them
> before the macro definition.
>
That's a really good and concise explanation of what occurs. IMO, it should be
part of the POV-Ray documentation, at "1.7-- Speed Considerations."
And perhaps this as well: For using a particular function in "math.inc" (or some
other include file), copy that entity into your main scene file, rather than
#including the entire #math.inc" file. (It can get complicated of course, if the
particular entity uses *another* entity within it.) ca> wrote:
>
> Parsing is strictly iterative and can only use a single thread.
>
> If you use any macro in a loop, it will get expanded and parsed each
> time it's used.
>
> If that macro is in an include file, that file will get opened and read
> each time the macro is invoked. EVERYTHING before the macro definition
> need to be read and skipped. Example : If you use any colour
> manipulation macro from colors.inc, they are located at the end, forcing
> the parser to read the whole include every time they are used...
> Cure : Copy any macro that is used in a loop into
> your main file. Remove any comment located within the macro, or move them
> before the macro definition.
>
That's a really good and concise explanation of what occurs. IMO, it should be
part of the POV-Ray documentation, at "1.7-- Speed Considerations."
And perhaps this as well: For using a particular function in "math.inc" (or some
other include file), copy that entity into your main scene file, rather than
#including the entire #math.inc" file. (It can get complicated of course, if the
particular entity uses *another* entity within it.)
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
Am 21.04.2018 um 21:30 schrieb Alain:
> If you use any macro in a loop, it will get expanded and parsed each
> time it's used.
>
> If that macro is in an include file, that file will get opened and read
> each time the macro is invoked.
As of v3.8.0-alpha, this is no longer true: Macros up to a certain size
(currently hard-coded to, IIRC, 64 kiB) are now cached in memory.
> EVERYTHING before the macro definition
> need to be read and skipped. Example : If you use any colour
> manipulation macro from colors.inc, they are located at the end, forcing
> the parser to read the whole include every time they are used.
That's not true even for v3.7 and earlier: The parser does remember the
offset of the macro within the include file, and jumps directly to that
offset when executing the macro.
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
Am 21.04.2018 um 18:38 schrieb Le_Forgeron:
> 2. I'm ready to help, I already have a debug version (with symbols in
> code) of povray and a profiling tool that does not slow down too much
> (not valgrind)
I'm pretty sure this isn't a matter of optimizing the hell out of any
particularly time-consuming function(s) participating in the parsing,
but rather of modifying the parser's fundamental way of operation.
For instance, POV-Ray's parser is comprised of:
(1) A /tokenizer/, which identifies the individual syntactic units in
the file (e.g. `#`, `define`, `MyVar`, `=`, `0.815`, `;`) and converts
each into an internal representation.
(2) An /interpreter/, which takes the stream of internal token
representations and interprets them.
Currently, the tokenizer is executed "on the fly", processing a single
token whenever the interpreter asks for the next one. This is true even
in loops, meaning that the loop body is re-tokenized all over again for
each iteration.
It would be faster to tokenize the entire file (or at least the loop
body) just once, keeping the internal representation in memory, and then
letting the interpreter loose on it.
This would also open up an opportunity for parallelization: One
dedicated tokenizer thread could go ahead processing the entire file,
while one dedicated interpreter thread could already start interpreting it.
But alas! Pulling the tokenizer and interpreter apart is not as easy as
it sounds, as POV-Ray's tokenizer currently goes one step too far: When
it comes to variable identifiers, its duty is not to just report
"potential variable identifier", but rather e.g. "unknown identifier" or
"variable holding a float" (*) -- which is impossible to decide outside
a particular interpreter context.
(* This is even true for array element access, e.g. `MyArray[I+1]` --
which even requires the tokenizer to recursively invoke the parser, to
evaluate `I+1` in this case.)
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
| |
|
|
Am 21.04.2018 um 17:03 schrieb Bald Eagle:
> Just for my own information, I'm wondering why POV-Ray is so painfully slow to
> process non-rendering information (parse time).
>
> I'm asking, because I converted some of Paul Nylander's Mathematica code for the
> reaction-diffusion algorithm to SDL, and although I knew beforehand that it has
> a fair amount of looping through a 'large' array (160x120), I was still somewhat
> amazed and dismayed that it was as slow as it was.
>
> This is thrown into even starker contrast when I run the reaction-diffusion code
> from Coding Challenge into Processing - which somehow manages to crank out
> results on a 700 x 500 grid at 60 frames per second (that's what's in the code,
> and the default speed - no idea if this is actual)
> I'm pretty sure Processing is as high a level language as SDL, and it's not
> compiled... so what IS the difference?
From the Processing web page:
"The idea of sketching is identical to that of scripting, except that
you're not working in an interpreted scripting language, but rather
gaining the performance benefit of compiling to Java class files."
So yes, Processing /does/ make use of compilation.
The fact that a language has an interactive mode (which /may/ be using
an interpreter) doesn't mean the language can't be compiled.
> Is there some sort of bottleneck or fundamental reason that the programmatic
> handling of data is so slow in comparison to other languages?
Yes, there is.
Every reasonably fast contemporary programming language makes use of at
least /some/ degree of compilation. For instance, functions, procedures
and/or classes might use proper compilation, or at least "compiled" into
an internal intermediate representation that is faster to interpret.
POV-Ray's parser is a genuine interpreter. No compiling going on /at
all/ (*)
(* Except for user-defined functions. Those are compiled into bytecode
for a proprietary virtual machine.)
The structure of POV-Ray's SDL differs significantly from that of
contemporary scripting languages, in that it is essentially a linear
data description language without any control flow (no branches, no
loops, no macros, no nothing), intermingled with an entirely different
scripting language providing control flow features /at the token level/;
i.e. the control flow portion of the language is blissfully unaware of
the structure of the data description language.
This allows constructs such as:
#ifdef(Object2)
union {
#end
object { Object1 }
#ifdef(Object2)
object { Object2 } }
#end
Note how this construct even defies indentation rules: You can indent it
according the control flow statements, /or/ you can indent it according
to the data description, but not both. And this is still a very tame
example compared to what's possible.
Worse yet, the variables mechanism woven into the whole smash can't be
clearly assigned to either of the two portions of the language: On the
one hand, it is an essential part to /drive/ the control flow (e.g. via
`#if(MyVar)`); on the other hand, they can be assigned values
/generated/ via the control flow language.
For example:
#declare Fnord = (Foo #ifdef(Add) + #else - #end Bar);
This makes it virtually(?) impossible not only to compile POV-Ray's SDL
as a whole, but also to even just compile its control flow portion into
a generator for a linear data description.
So in order to really speed up parsing, you'd need to re-invent
POV-Ray's language.
Post a reply to this message
|
|
| |
| |
|
|
|
|
| |
|
|